
tokenize的目标是把输入的文本切分成一个个子串,便于embedding处理和后续模型的使用。本文总结了Tokenize流程、方法和特点,并使用Huggingface库和tiktoken库做了示例。
tokenizer工作流程
大致工作流程: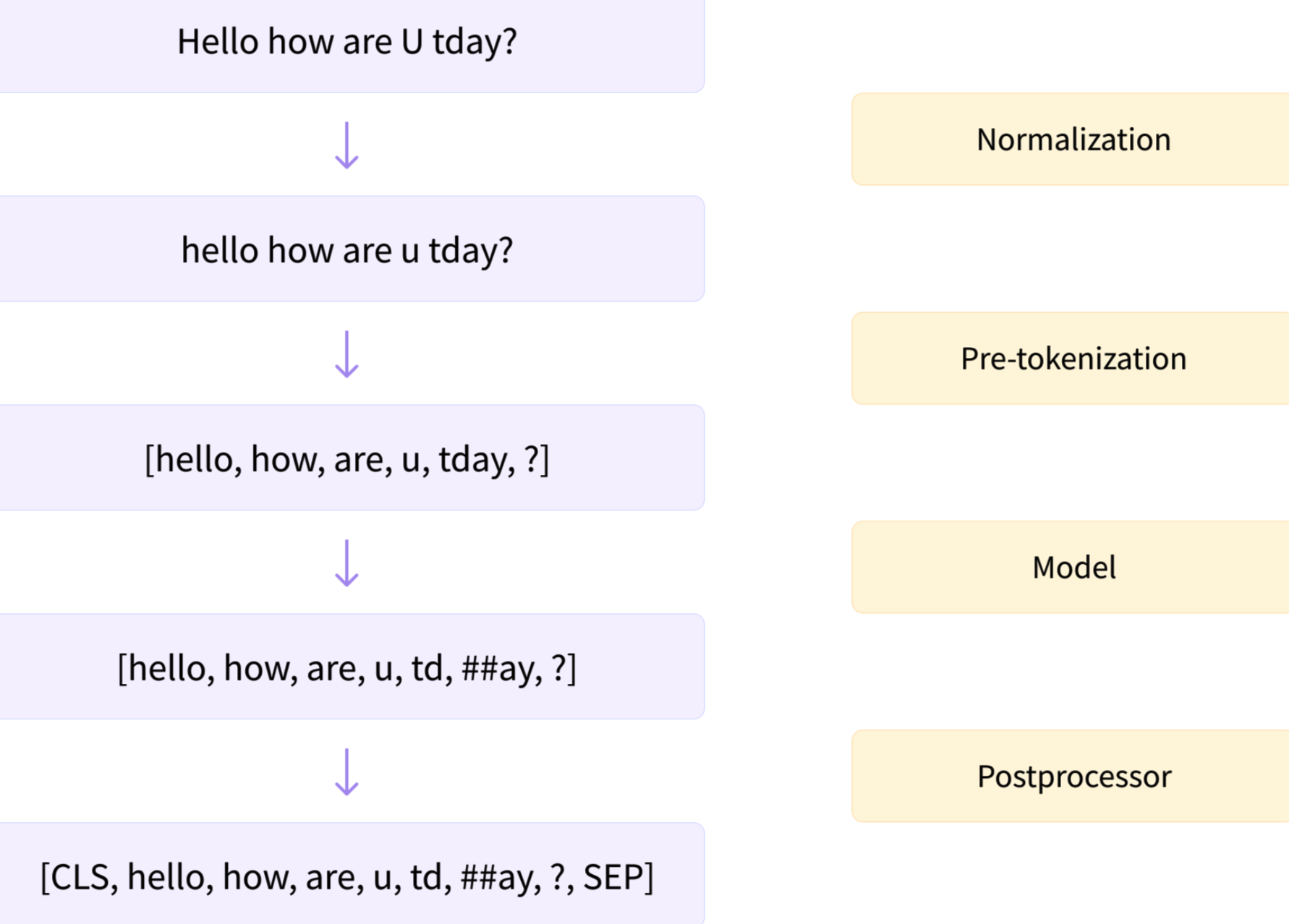

Normalization:
涉及一些常规清理,例如删除不必要的空格、小写和/或删除重音符号。
Pre-tokenization:
分词器不能单独在原始文本上进行训练。相反,我们首先需要将文本拆分为小实体,例如单词。
Model:
如果需要在自己的数据集上训练一个新的tokenizer,就构建模型训练个。
PostProcessors:
添加特殊的符号,例如 SEP, CLS等
特点
主要有三种切分粒度:word/词级别、char/字符级别、subword/子词级别,各自特点总结:
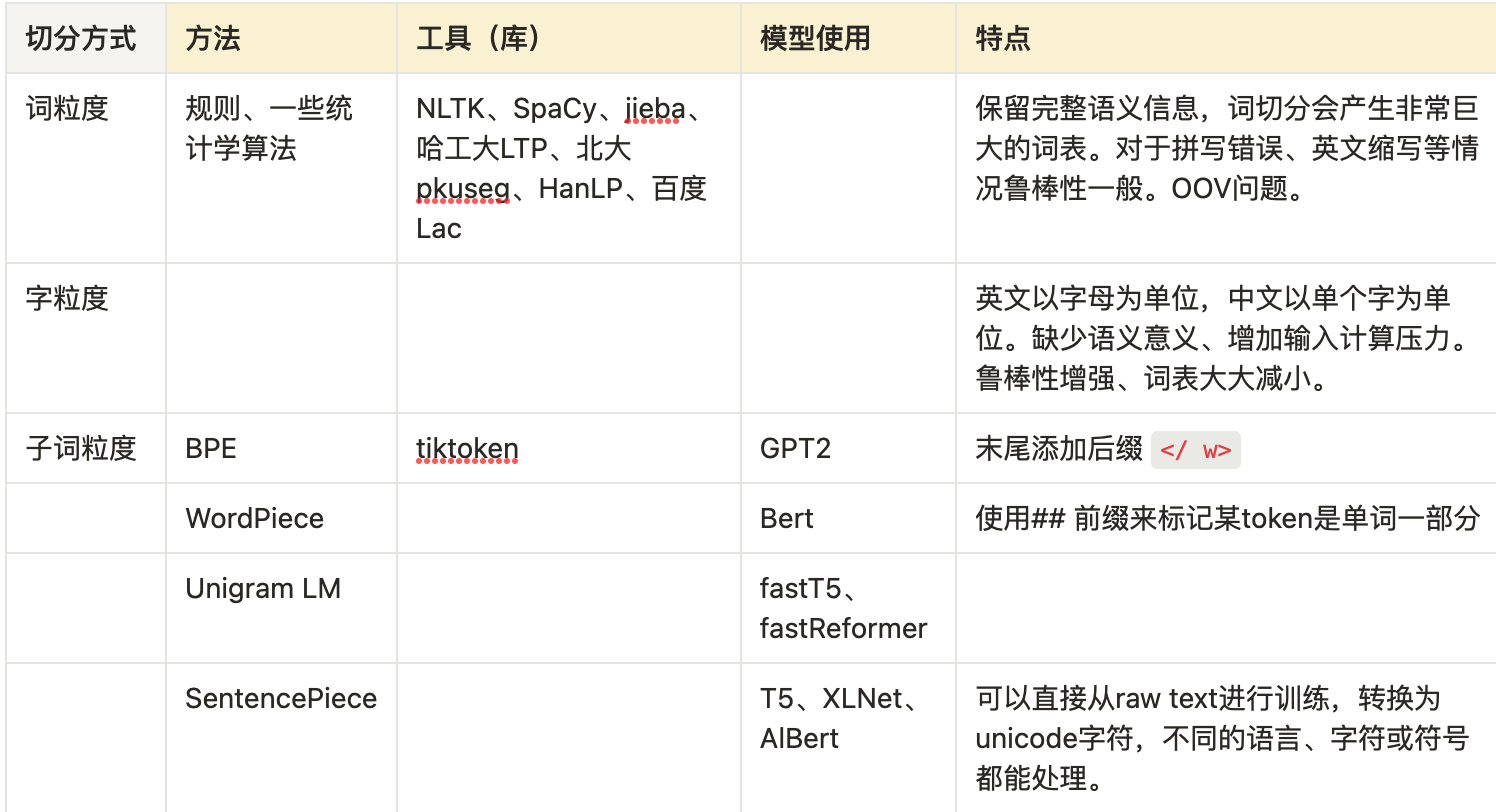
tokenizer切分算法

下面的示例,我们使用一句话,encode之后再decode看看结果的异同就能直观感受到这几个的异同了:
text = '马来亚大学 university of malaya'BPE(Byte-Pair Encoding)算法
BPE全称Byte Pair Encoding 字节对编码,首先在Neural Machine Translation of Rare Words with Subword Units 中提出。BPE 通过迭代方式合并最频繁出现(出现频率)的字符或字符序列,直到达到预定义的词汇表大小停止。
HuggingFace 中相关模型的 Tokenizer 示例:
from transformers import GPT2Tokenizer
BPE_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
bpe_token_ids = BPE_tokenizer.encode(text)
bpe_tokens = [BPE_tokenizer.decode(token) for token in bpe_token_ids]
print(f"bpe_token ids: {bpe_token_ids}")
print(f"bpe_tokens: {bpe_tokens}")
# bpe_token ids: [165, 102, 105, 30266, 98, 12859, 248, 32014, 27764, 99, 6403, 286, 6428, 11729]
# bpe_tokens: ['�', '�', '�', '�', '�', '�', '�', '大', '�', '�', ' university', ' of', ' mal', 'aya']结果中有乱码,重新decode一下: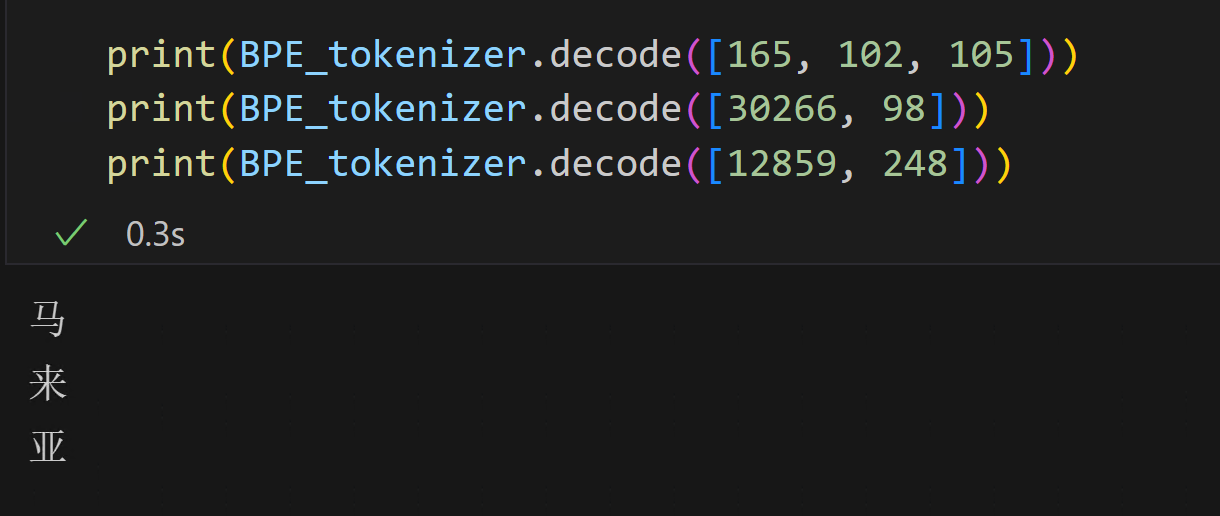
或者用openai的 tiktoken 库:
import tiktoken
tiktoken_encoder = tiktoken.get_encoding("gpt2")
tiktoken_ids = tiktoken_encoder.encode(text)
token_bytes = [tiktoken_encoder.decode_single_token_bytes(token) for token in tiktoken_ids]
print(f"tiktoken_ids : {tiktoken_ids}")
print(f"tiktoken bytes: {token_bytes}")
# tiktoken_ids : [165, 102, 105, 30266, 98, 12859, 248, 32014, 27764, 99, 6403, 286, 6428, 11729]
# tiktoken bytes: [b'\xe9', b'\xa9', b'\xac', b'\xe6\x9d', b'\xa5', b'\xe4\xba', b'\x9a', b'\xe5\xa4\xa7', b'\xe5\xad', b'\xa6', b' university', b' of', b' mal', b'aya']每个字符前面的 b 表示字符串是字节字符串这个tiktoken 特别快,官方给了评测: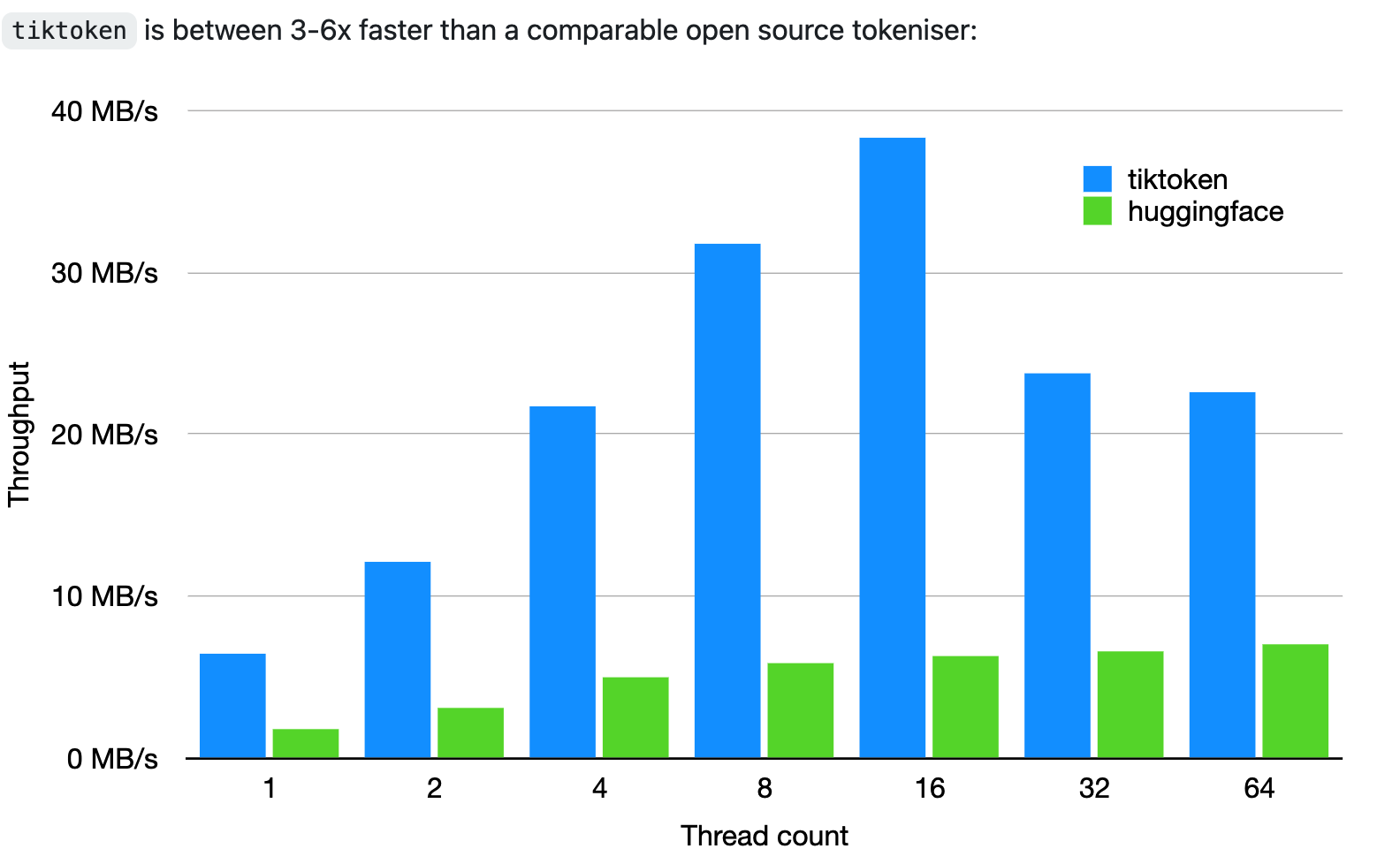
WordPiece算法
WordPiece 使用 greedy算法,首先试图构建长单词,当整个单词在词汇表中不存在时,就会分成多个标记。用 ## 前缀来标记某token是单词一部分,而不是单词开头。
from transformers import BertTokenizer
# BertTokenizer/WordPiece
WordPiece_tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
wp_token_ids = WordPiece_tokenizer.encode(text)
wp_tokens = [WordPiece_tokenizer.decode(id) for id in wp_token_ids]
print(f"token ids: {wp_token_ids}")
print(f"wp_tokens : {wp_tokens}")
# 结果:
# token ids: [101, 7716, 3341, 762, 1920, 2110, 8736, 8205, 9622, 11969, 8139, 102]
# wp_tokens : ['[ C L S ]', '马', '来', '亚', '大', '学', 'u n i v e r s i t y', 'o f', 'm a', '# # l a y', '# # a', '[ S E P ]'] 除了单个字和单词,还有 '## lay', '## a'标记。
除了单个字和单词,还有 '## lay', '## a'标记。
Unigram LM
Unigram LM 方法基于概率LM,子词序列由子词出现概率的乘积生成,移除那些提高整体可能性最小的token,迭代直到达到预定义的词表大小。
SentencePiece算法
SentencePiece 算法把一个句子看作一个整体,转换为unicode字符,再拆成片段,把空格space也当作一种特殊字符来处理,用BPE或者UniLM来构造词汇表。
from transformers import XLNetTokenizer
SentencePiece_tokenizer = XLNetTokenizer.from_pretrained("hfl/chinese-xlnet-base")
sp_token_ids = SentencePiece_tokenizer.encode(text)
sp_tokens = [SentencePiece_tokenizer.decode(token) for token in sp_token_ids]
print(f"sp_token ids: {sp_token_ids}")
print(f"sp_tokens: {sp_tokens}")
# sp_token ids: [19, 19223, 326, 19, 2394, 1110, 15984, 5812, 19, 16636, 19, 17018, 18808, 4, 3]
# sp_tokens: ['', '马来亚', '大学', '', 'un', 'i', 'vers', 'ity', '', 'of', '', 'mal', 'aya', '<sep>', '<cls>']