




本篇关于编程之美和Python高阶使用的探索。
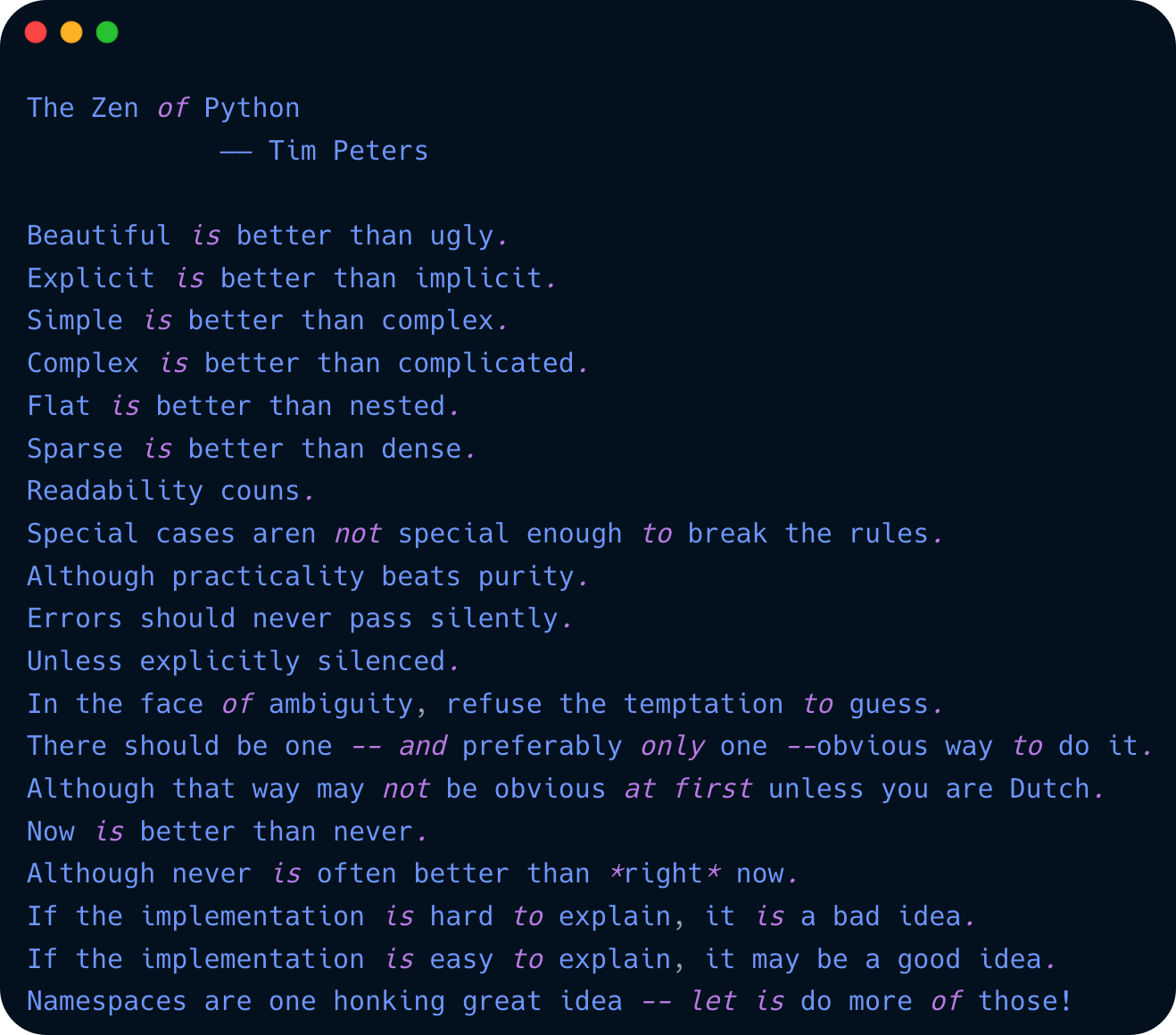
在实现Python功能的同时,兼顾代码之美、简洁、优雅、易读,正如编程之禅The Zen of Python中提到的:
Part1列表、集合、字典
使用列表推导式可以快速生成一个列表
# 列表推导
result = [_ for _ in range(10)]
result = [i for i in range(10) if i % 2 == 0]
列表切片也经常用到
# 列表切片 [start : stop : step]
s = sum(a[1::2])
del a[::2]
# 回文检查
# 回文是一系列正向和反向读取相同的字符。通常要用循环和条件来检查字符串是否是回文,
# 但我们只需要切片运算符[::-1]就可以,还可以使用使用reverse()函数来反转字符串
phrase = 'deleveled'
isPalindrome = phrase == phrase[::-1]
print(isPalindrome) # True
我们也经常要对多个变量赋值,要挨个定义和赋值吗?
这里我们用星号* 来解构赋值,将列表元素分配给给定的变量,这也称为拆包。用*打包剩余的值,这会产生一个子列表c。
# 一次赋值多个变量
a, b, *c = [1,2,3,4,5]
print('星号* 来解构赋值: ',a,b,c)
# 星号* 来解构赋值: 1 2 [3, 4, 5]
# 可以更换* 位置
* a, b, c = [1,2,3,4,5]
print('更换* 位置: ',a,b,c)
# 更换* 位置: [1, 2, 3] 4 5
# 变量交换
a, b = b, a
print('a, b变量交换: ', a,b,c)
# a, b变量交换: 4 [1, 2, 3] 5
上面用到号来解构赋值,也可以用星号 来解包可迭代对象。例如,我们想要把一个列表、一个元组和一个集合合并成一个列表:
a = [1, 2, 3]
b = (4, 5, 6)
c = {7, 8, 9}
new_list = [*a, *b, *c]
print('合并列表、元组和集合: ',new_list)
# 合并列表、元组和集合: [1, 2, 3, 4, 5, 6, 8, 9, 7]
列表中查看出现频次最高的元素:
# list列表中出现频率最高的元素
a = [1, 2, 3, 1, 2, 3, 2, 2, 4, 5, 1]
print(max(set(a), key = a.count))
from collections import Counter
print(Counter(a).most_common(1))字典的常用操作中,我们需要返回排序字典:
# 字典排序
d = {'apple': 9900, 'huawei':5500, 'vivo': 4300}
print(sorted(d, key=d.get))
print(sorted(d.items(), key=lambda x: x[1]))
字典更新,如果我们需要合并字典,最简单方法——联合运算符 | 即可:
location = {'杭州市': '浙江省',
'南京市': '江苏省'}
people = {'马云': '杭州市',
'马化腾': '深圳市'}
# 三种方式都可以
print(people|location)
print({**people, **location})
people.update(location)
print(people)
# {'马云': '杭州市', '马化腾': '深圳市', '杭州市': '浙江省', '南京市': '江苏省'}
Part2链式比较、三元运算符
age = 1
# 比较链
if 60 < age < 100:
print("(60 ~ 100)")
else:
# 链式比较
print(1 < age < 9) # False
print(1==age < 10) # True
# if else 三元条件运算符
small = a if a < b else b
Part3else不只和if组合
我们在执行for循环的时候,可以用for else做循环检测
for i in range(5):
if i == 10:
break
else:
print("如果没有执行过 break 语句就执行这个流程")
while else 同理:
while False:
pass
else:
print("this is else block")
在使用try的时候,也可以else:
# try else
try:
pass
except Exception as err:
pass
else:
print("this is else block")
finally:
print("finally block")
Part4使不使用if判断?
如果我们使用if做条件判断,返回的结果是True或False的话,可以简洁写成:
if condition:
pass
if not condition:
pass
if condition is None:
pass
那如果不想写if-elif-else呢?
如果只是返回True或False,还有个简单的办法,就是使用any():
# 可迭代对象的任何元素为真,则 any 返回 True
# 检查列表中是否至少有一个正元素
num_list = [1, -2, 0, 5, -0.1]
any(n>0 for n in num_list)
有很多不是True or False的情况,有多个条件需要判断的时候,怎么处理呢?
在Python中我们可以使用字典的方式,以字典键作为不同case即可实现(其一):
# 用字典以 case 为键,要执行的函数对象为值,这样做到按 case 路由
map_dict = {
1: function(),
2: function(),
3: function()
}
# case_id = 1、 2、 3
map_dict[case_id](100 * case_id)
如果case有好多个,写起来也不优雅,我们可以使用查找表或者enumerate() 的方式代替字典(其二、三):
# 小写字母a-z的值为1到26,大写A-Z的数值为27到52,实现给字母返回值:
letters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
def Letter_value(letter: str) -> int:
return 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'.index(letter)
# 或者用 enumerate
# 将 range(len) 替换为枚举
for idx, letter in enumerate(letters, start=1):
print(idx, letter)
在Python 3.10版本,引入了match case 语法也可以实现(其四):
def main(case_id: int):
match case_id:
case 1:
function()
case 2:
function()
case 3:
function()
Python不是还有枚举enum包吗?
根据不同的情况枚举一下,也可以实现不写if-else(其五):
from enum import Enum
class Days(Enum):
MONDAY = 1
TUESDAY = 2
WEDNESDAY = 3
THURSDAY = 4
FRIDAY = 5
SATURDAY = 6
SUNDAY = 7
def str_num_map(day: str) -> int:
return Days[day].value
str_num_map('WEDNESDAY')
使用Enum会使代码更简短,增加可读性(所见即所得),同时能做到类型安全。当对其进行扩展时,采用if-else的方法会变得越来越糟糕,而Enum则相对容易保持可读性。
Part5生成器还可以这么用
有的时候我们不得不做循环嵌套,但是Python中,我们可以不写嵌套循环,即可实现功能,就是使用itertools模块的product()函数来避免嵌套循环:
# 题目:三个列表中int元素,判断和等于100时打印元素
from itertools import product
list_a = [1, 50, 70]
list_b = [2, 30, 7, 99]
list_c = [3, 20, 0]
for a, b, c in product(list_a, list_b, list_c):
if a + b + c == 100:
print(a, b, c)
# 1 99 0
# 50 30 20
# 70 30 0
关于生成器,有时候我们要在for 循环中yield出元素,但替换yield from可以消除了对可迭代对象的手动循环:
# 生成器, 对于可迭代对象有yield from 关键字
# for item in iterable: yield item 改为:yield from iterable
def get_content(entry):
yield from entry.blocks()
Part6高效装饰器
@contextmanager: 上下文管理器机制来帮助我们正确地管理资源。
@property:面向对象编程 (OOP) 中,getter访问器 和 setter修改器用于保护数据不被直接和意外地访问或修改。
@cached_property:将一个类的方法转换为一个属性,该属性的值计算一次,然后在实例的生命周期内作为普通属性缓存。避免对同一实例的属性进行重复计算。
@classmethod:绑定到类的方法。他们不能修改实例数据。在类本身上调用类方法,它接收类作为第一个参数,通常命名为 cls。
@staticmethod:静态方法不绑定到实例或类。它们被包含在一个类中只是因为它们在逻辑上属于那个类。
@dataclass:自动生成一些special method并添加到类中,如__init__、__repr__、__eq__、__lt__等。
@atexit.register:可以让Python解释器在退出时执行一个函数。比如在执行最终任务时,释放资源或说再见,而不需要显式调用
@lru_cache: 缓存一个函数的结果,后续调用相同参数的函数就不会再执行了,对于计算量大或使用相同参数频繁调用的函数特别有用。
@total_ordering: 用于根据定义的方法为类生成缺少的比较方法,比如大于、等于、小于。在functools模块中。
接下来,我们主要讲解contextmanager和dataclass这两个装饰器。
1上下文contextmanager
使用 contextmanager 的 manager装饰器实现了内容管理协议。这里结合了with关键字,with语句除了用来打开文件或获取锁,例如 with open()..., 我们还可以用它实现上下文管理。
from contextlib import contextmanager
@contextmanager
def make_tag(tag):
print(f"<{tag}>")
yield
print(f"</{tag}>")
with make_tag("h1"):
print("我是h1一级标题")
# <h1>
# 我是h1一级标题
# </h1>
这里执行逻辑:
在进入 with 块时 tag()函数的第一部分(在 yield 之前的部分)就已经执行了,然后 with 块才被执行,最后执行 tag 函数的其余部分。
2dataclass
我们在处理数据的时候,传统的,我们用__init__ 给对象属性赋值,或者在类中的方法前加上@property 属性装饰器(语法糖)。
这里我们在类前加上@dataclass,就不需要我们显示的定义init,因为这个装饰器会自动帮我们把需要的自动执行好。
从官方给的解释就能看出,给类前加了这个装饰器,会自动添加__init__() 、__repr__()等方法。
def dataclass(cls=None, /, *, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False, match_args=True,
kw_only=False, slots=False)
Returns the same class as was passed in, with dunder methods added based on the fields defined in the class.
If init is true, an __init__() method is added to the class.
If repr is true, a __repr__() method is added.
If order is true, rich comparison dunder methods are added.
If unsafe_hash is true, a __hash__() method function is added. If frozen is true, fields may not be assigned to after instance creation.
If match_args is true, the __match_args__ tuple is added.
If kw_only is true, then by default all fields are keyword-only.
If slots is true, an __slots__ attribute is added.
下面是一个人名信息示例,只需要短短几行代码就完成了类的定义和调用。
from dataclasses import asdict, dataclass
@dataclass
class Person(object):
first_name: str
last_name: str
phone: int
if __name__ == "__main__":
info = Person("旭源","程",18877779999)
print(asdict(info))
# {'first_name': '旭源', 'last_name': '程', 'phone': 18877779999}
Part7其他Python操作
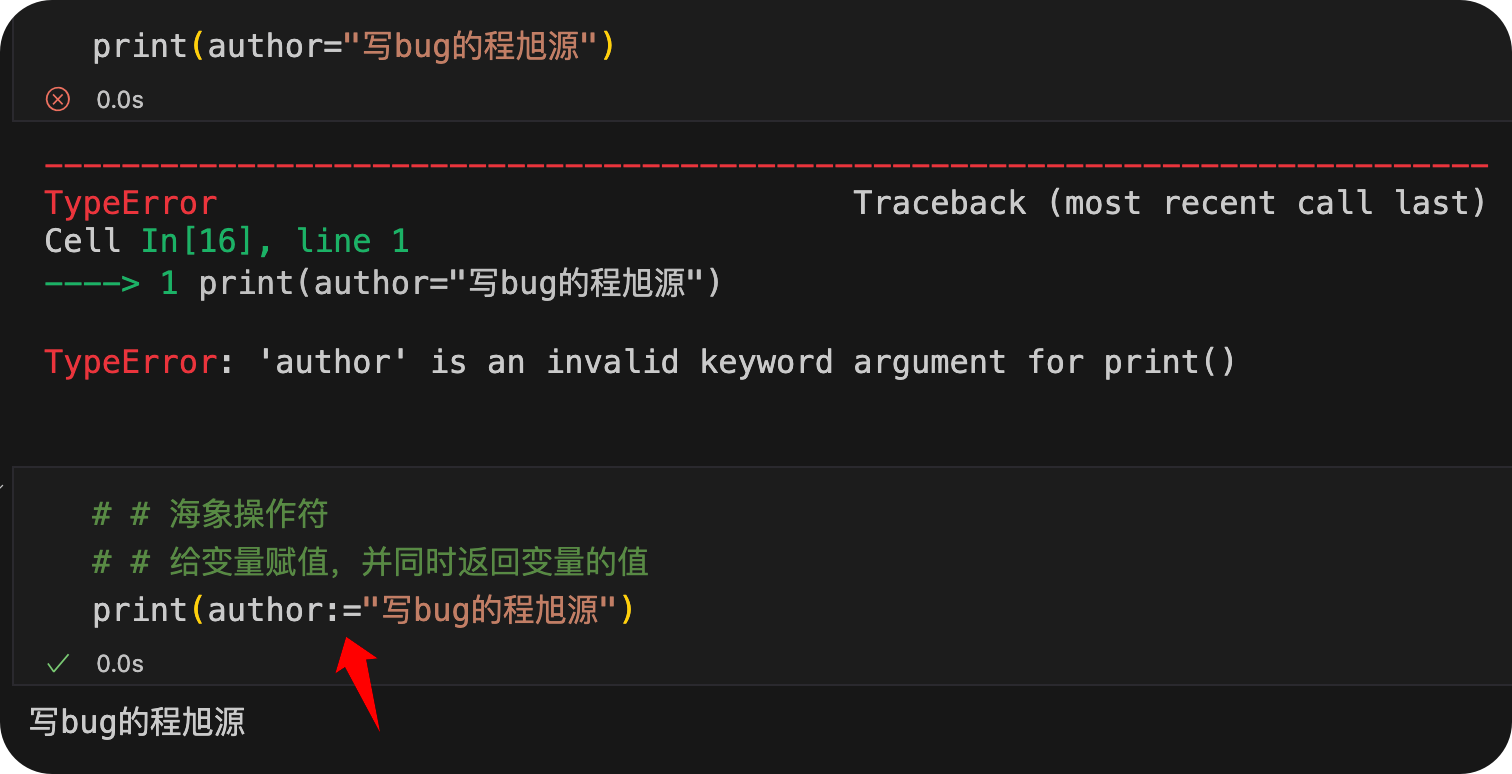
3海象操作符
我们使用海象操作符可以给变量赋值的同时返回变量的值,从而简写代码:
print(author:="写bug的程旭源")
4Lambda函数
Lambda函数来定义简单函数,省去定义函数的过程,对于不需要多次复用的函数,用lambda表达式可以在用完后立即释放:
lambda 变量(变量列表): 表达式
例如判断奇偶数和列表排序:
odd_or_even = lambda x: "偶数" if x % 2 == 0 else "奇数"
print(odd_or_even(10)) # 偶数
# 列表排序
a = [(2, "TUESDAY"), (5, "FRIDAY"), (1, "MONDAY"),(4, "THURSDAY"), (3, "WEDNESDAY"), (6, "SATURDAY"), (7, "SUNDAY")]
a.sort(key=lambda x: x[0])
5map 和 reduce
map() 函数是经常使用的高阶函数,将可迭代对象中元素逐个映射:
who = ['xie','buG', 'de','cHeng', 'xu', 'yUaN']
names = map(str.capitalize, who)
print(list(names))
# ['Xie', 'Bug', 'De', 'Cheng', 'Xu', 'Yuan']
reduce()函数将可迭代对象中每个元素按照传入reduce的函数功能进行操作:
from functools import reduce
city = ['H', 'a', 'n', 'g', 'Z', 'h', 'o', 'u', 2, 0, 2, 3]
def concat_str(x, y):
return str(x) + str(y)
city_to_str = reduce(concat_str, city)
print(city_to_str) # HangZhou2023
# 或者
city_to_str = reduce(lambda x, y: str(x) + str(y), city)
print(city_to_str) # HangZhou2023
6F-string字符串格式化技术
有时候我们print的时候,想要格式化输出,可以在字符串前加f:
pi = 3.1415926
print(f'Pi 约等于 {pi:.2f}')
# Pi 约等于 3.14
N = 100000
print(f'100000 添加分割符: {N:,d}')
# 100000 添加分割符: 100,000
from datetime import datetime
print(f"现在日期时间是: {datetime.today()}")
# 现在日期时间是: 2023-02-26 12:48:19.498393
7文本清洗
文本处理对于做NLP的同学来说,是一个重头戏,我们除了使用正则表达式,还可以使用unicodedata包和combining()函数去生成和重映射表。使用字符串的translate()方法,调用映射字典完成操作。这里的ord()函数可以检测所给的Unicode字符是否超出了Python定义范围,超出则会引发一个TypeError异常。
user_input = "杭州n明天t又是一个好天气...rn"
character_map = {
ord('n') : '',
ord('t') : '',
ord('r') : None
}
user_input.translate(character_map)
# '杭州明天又是一个好天气...'
关于文本处理还有很多可以做,这里仅仅举了一个例子。
本次分享就到这里啦,欢迎文末留言交流。由于作者水平有限,未尽之处请不吝赐教。


2023-02-02

2023-02-02

2023-01-29

 星标公众号,精彩不错过
星标公众号,精彩不错过


“点赞”是喜欢,“在看、分享”是真爱
<