


本文探索云原生向量数据库Milvus的安装和使用,使用Langchain和港大的Instruction-XL模型做本地数据的切分和转向量,为那些无法使用OpenAIEmbeddings、不想将数据外泄到境外的项目提供了一个示例。
Milvus架构和简介
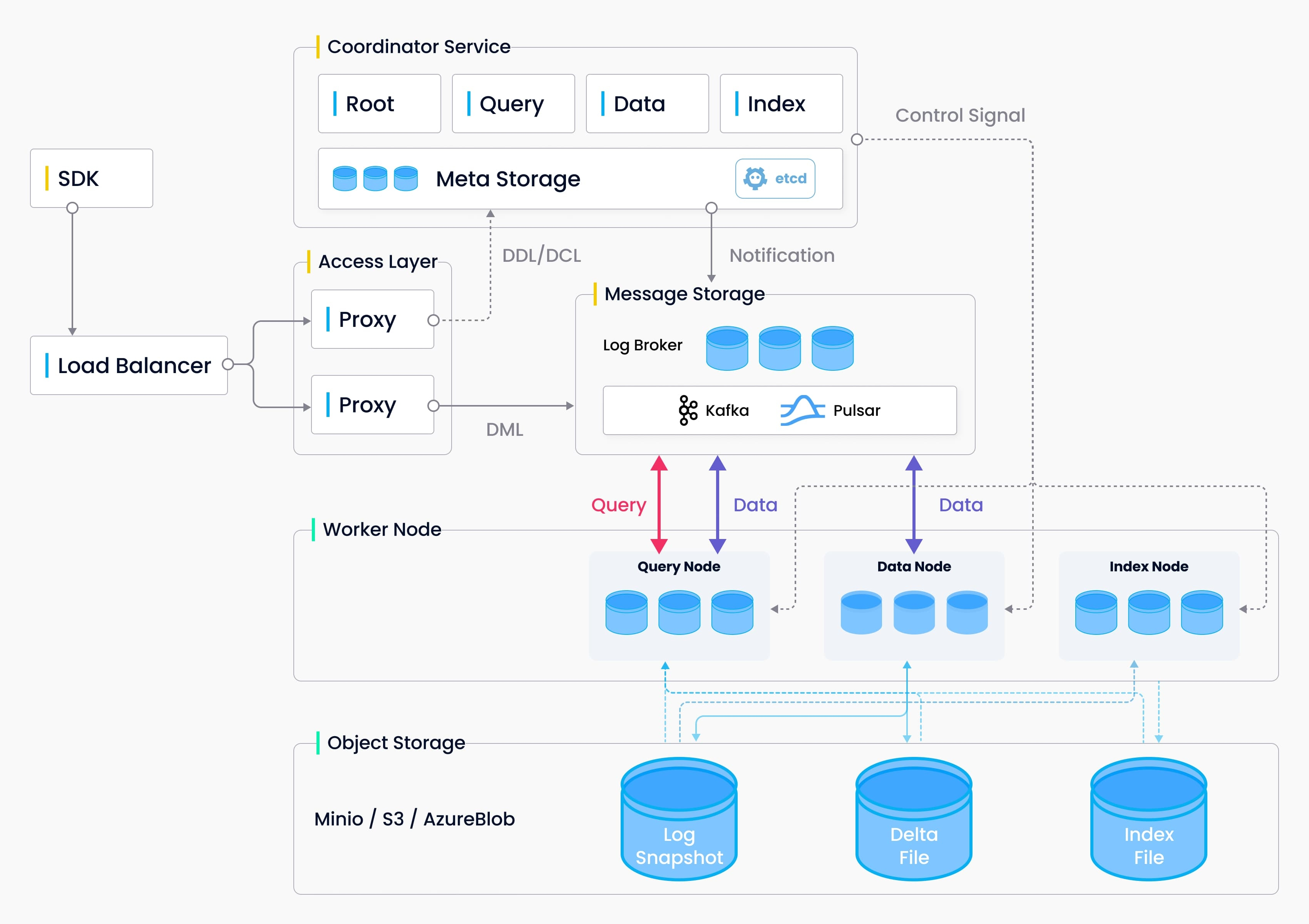
是一个云原生向量数据库,主要开发语言是Go和Python。
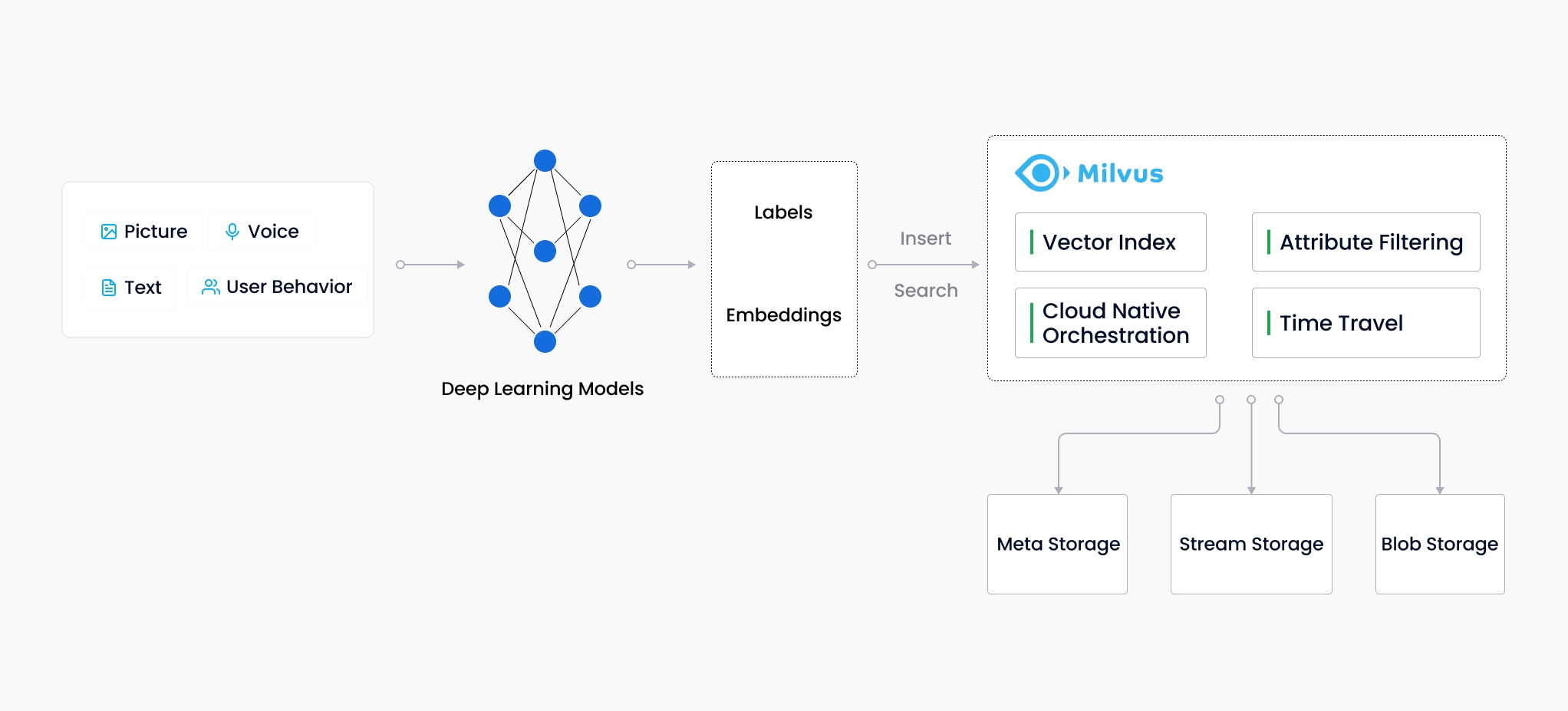
支持文本、语音、图像等原始材料经过模型转换成向量后,都可以存储在Milvus中。
Windows MacOS和Ubuntu都可安装:

相关的效率工具
-
Milvus_CLI
命令行工具 -
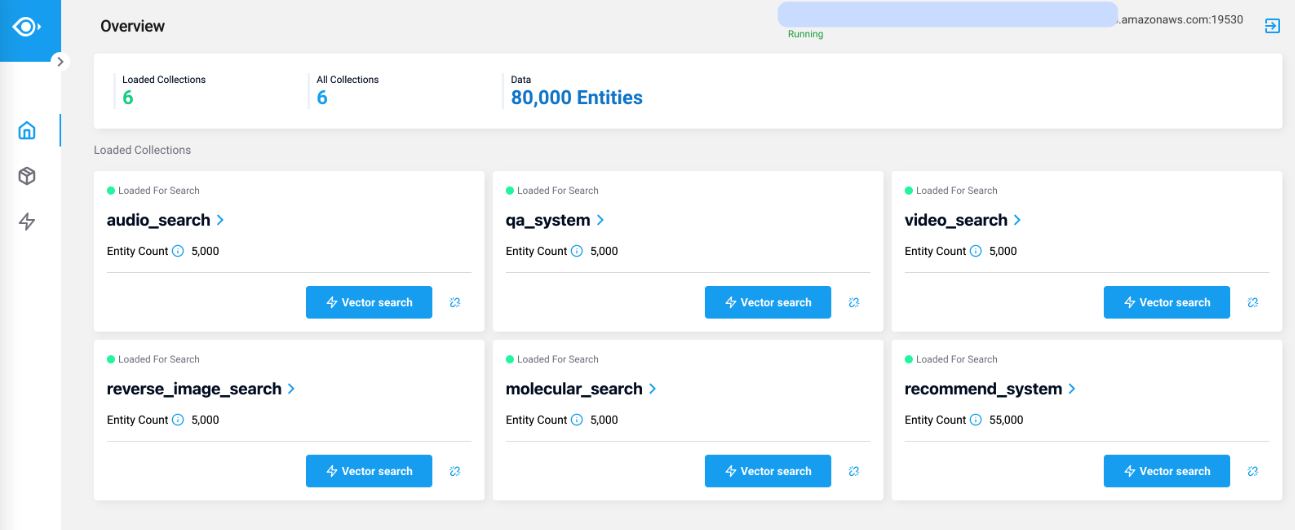
界面:Attu 图形管理系统
-
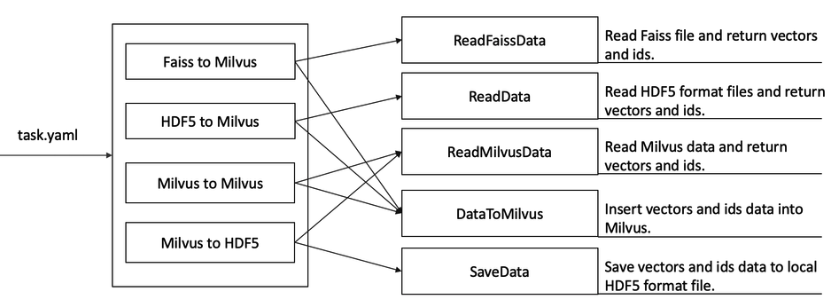
MilvusDM:用于导入和导出Milvus数据。
- Milvus API: 在Milvus API之上封装了客户端库,可用于从应用程序代码以编程方式插入、删除和查询数据.
安装
Docker安装
Windows 上Docker安装,要选择Use WSL2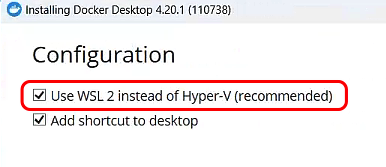
一键自动化安装完,登录即可
如果Windows上安装了WSL(Windows Ubuntu 子系统),终端cmd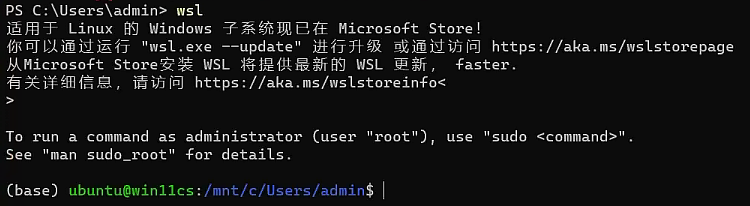
Ubuntu和Mac上安装参考 Ubuntu和Mac Docker安装
后面如果想要在WSL中使用,需要在Windows中启动Docker Desktop。
在settings下General中,确保启用了wsl引擎。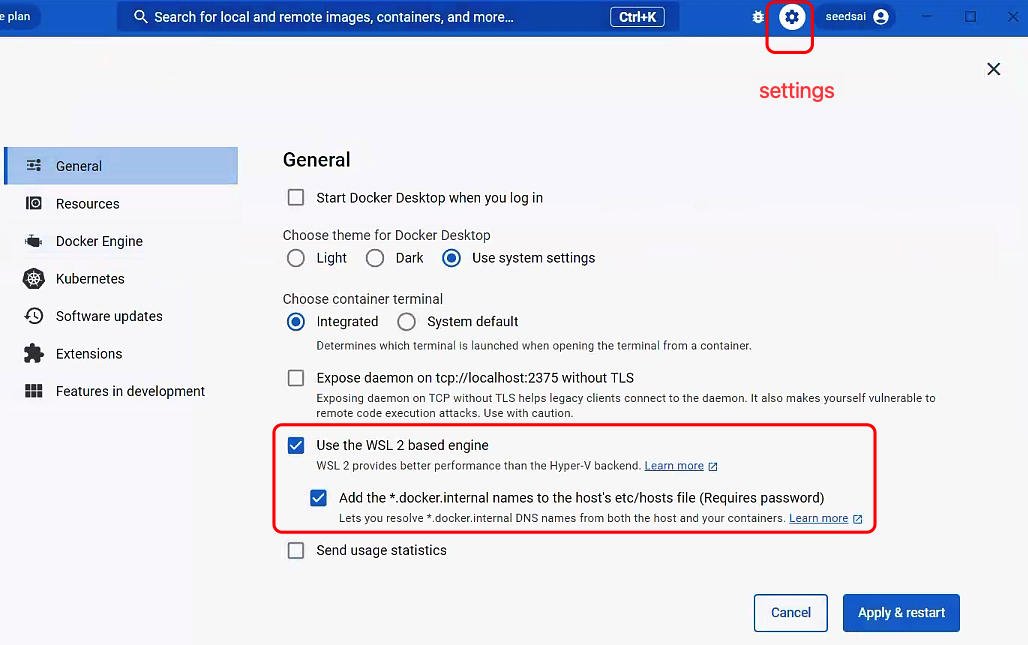
启用前后,可以使用:docker compose version查看一下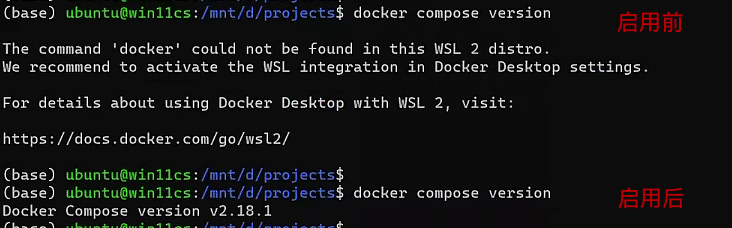
安装Milvus
这里介绍在Windows子系统(Ubuntu)中使用Docker安装的步骤~
第一步:下载 docker-compose.yml
可以在终端上执行命令:
wget https://github.com/milvus-io/milvus/releases/download/v2.2.9/milvus-standalone-docker-compose.yml -O docker-compose.yml或者创建docker-compose.yml然后复制下面内容粘贴进去:
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.2.9
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus(base)上面我们使用 docker compose version 命令查看了版本号,
如果是v1,运行命令:
sudo docker-compose up -d
如果v2,运行命令:
sudo docker compose up -d
运行完:
可以检测一下是否启动了docker container:
sudo docker-compose ps

显然已经启动起来了。
关掉容器:
sudo docker-compose down
删除数据【慎用】:
sudo rm -rf volumes
执行后可就全没了啊~
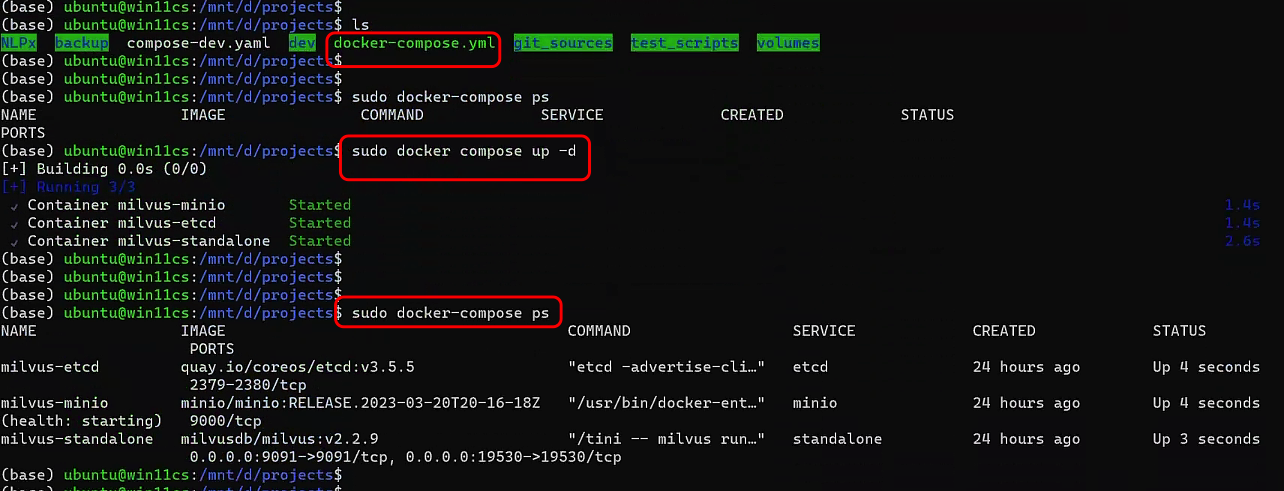
如果关掉了容器,下次启动只需要找到我们compose-up.yaml文件目录,按照图中的命令执行一下即可(命令都在上文中)
langchain+Milvus实践
今天我们探索Python操作Milvus,将文本转换成向量并存储。
安装 pymilvus:
pip install pymilvus
这里我们使用港大最新的instruction-xl做文本embedding转换模型,而不是网上那么多教程都是使用CloseAI的:embeddings = OpenAIEmbeddings()。
此处的数据就直接使用了milvus介绍页的英文
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Milvus
MILVUS_HOST = "localhost"
MILVUS_PORT = "19530"
# 数据加载器
# pip install bs4
loader = WebBaseLoader([
"https://milvus.io/docs/overview.md",
])
docs = loader.load()
# 数据分割
text_splitter = CharacterTextSplitter(chunk_size=1024, chunk_overlap=0)
docs = text_splitter.split_documents(docs)embedding模型选择
上面数据就分块好了,接下来我们看看如何用langchain本地转向量操作:这里我们不使用 OpenAIEmbeddings()。
- 普通 sentence embedding
from langchain.embeddings import HuggingFaceEmbeddings
# 为空,默认是 "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings()
query_result = embeddings.embed_query(query)- 指令类embedding
from langchain.embeddings import HuggingFaceInstructEmbeddings
# 默认是:"hkunlp/instructor-large"
embeddings = HuggingFaceInstructEmbeddings(
model_name = "hkunlp/instructor-xl",
embed_instruction = "Represent the document for retrieval: "
)我们使用指令类embedding 将上面的docs文档,转换成embedding 向量, Milvus存储:
milvus_db = Milvus.from_documents(
docs,
embedding=embeddings,
connection_args={"host": MILVUS_HOST, "port": MILVUS_PORT}
)试试Milvus基于相似度的向量问答:
query = "What is milvus?"
smi_docs = milvus_db.similarity_search(query)
from pprint import pprint
pprint(smi_docs[0])