


关注我们

一起成长
关注我们
一起成长


目录:
-
1、基本元字符含义 -
2、常用符号和组合释义 -
3、常用正则函数 -
4、常用正则表达式工具
Part1正则基础元字符
关于正则表达式的基础语法和字符释义讲解。
1常用元字符
元字符有. [ ] () ^ $ | ? * + { }共11种
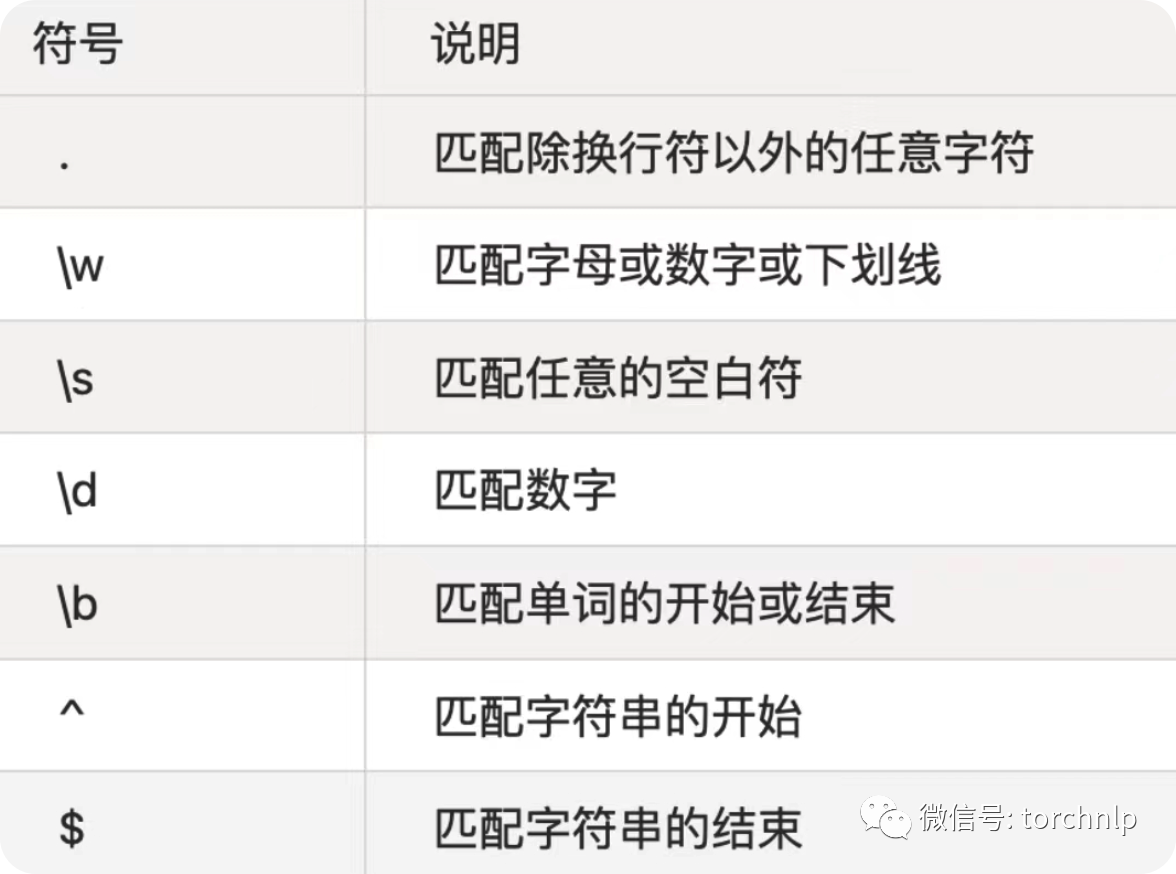
:为转义字符
w:等同于[a-zA-Z0-9_];匹配字母数字及下划线
W:与w相反;[^a-zA-Z0-9_]
s:[ fnrtv];匹配任何空白字符,包括空格、换页符、换行符、回车符、制表符
S:与S相反;[^ fnrtv]
d:匹配任意数字,[0-9]
D:与D相反,[^0-9]
A:匹配字符串开始
Z:匹配字符串结束,如果存在换行,只匹配到换 行前的结束字符串
z:匹配字符串结束
G:匹配最后匹配完成的位置
b:匹配单词边界,也就是单词和空格之间的位置
B:匹配非单词边界
2常用量化符
量化符也叫重复修饰符,将紧挨着量化符前面的那个字符,匹配0次、1次或者多次。

在 ?, +?, ??中,'', '+',和 '?' 修饰符都是 贪婪的,在字符串进行尽可能多的匹配。
在修饰符之后添加 ? 将使样式以非贪婪方式或者最小方式进行匹配;尽量 少的字符将会被匹配。
*:数量词,匹配其前面字符的任意0,1或多次。
.*:匹配任意长度的任意字符,最长匹配,即贪婪模式
?:匹配其前面的字符0次或1次
+:匹配其前面的字符1次或多次
{n,}:数量匹配,重复n次或多次
{n,m}:数量匹配,重复n-m次
懒惰限定符:
*? :重复任意次,但尽可能少重复
+? :重复 1 次或更多次,但尽可能少重复
?? :重复 0 次或 1 次,但尽可能少重复
{n,}?:重复 n 次以上,但尽可能少重复
{n,m} :重复 n 到 m 次,但尽可能少重复
边界位置字符
指定匹配字符的位置。
^:匹配开头,多行模式匹配每一行的开头
$:匹配结尾,多行模式中匹配每一行的结尾
b:单词边界
B:与b相反
A:仅匹配字符串开头
Z:仅匹配字符串结尾
Part2常用符号示意
除了上面常用的字符、次数和位置限定等,还有一些组合也会经常用到。
|:匹配两边任一
():匹配括号内的表达式作为分组
(?P<name>...):为子模式命名
number:引用指定编号分组匹配到的字符串
(?P=name):引用使用别名分组匹配到的字符串
(?:...):不分组,用于使用|或后接数量词
(?iLmsux):每个字符代表一个匹配模式,只能用在正则表达式的开头
(?#...):# 后的内容可作为注释被忽略
(?=...):之后的字符串内需要匹配表达式才能匹配成功。
(?!...):之后的字符串内容需要不匹配表达式才能成功匹配
(?<=...):之前的字符串内容需要匹配表达式才能成功匹配
(?<!...):之前的字符串内容需要不匹配表达式才能成功匹配
3常用模块
re.A (只匹配ASCII字符), re.I (忽略大小写),
re.L (语言依赖), re.M (多行模式), re.X (冗长模式),
re.S (点dot匹配全部字符), re.U (Unicode匹配),

4[] 字符集合
字符可以单独列出,比如 [amk]匹配'a''m'或者'k'。
可以表示字符范围,通过用 '-' 将两个字符连起来。比如 [a-z] 将匹配任何小写ASCII字符, [0-5][0-9] 将匹配从 00 到 59 的两位数字, [0-9A-Fa-f] 将匹配任何十六进制数位。如果 - 进行了转义(比如 [a-z])或者它的位置在首位或者末尾(如 [-a] 或 [a-]),它就只表示普通字符 '-'。
特殊字符在集合中会失去其特殊意义。比如[(+)]只匹配(','+',')字面字符。
字符类如 w 或者 S (如下定义) 在集合内可以接受,它们可以匹配的字符由 ASCII 或者 LOCALE 模式决定。
不在集合范围内的字符可以通过 取反 来进行匹配。如果集合首字符是 '^' ,所有 不 在集合内的字符将会被匹配。比如 [^5] 将匹配所有字符,除了 '5', [^^] 将匹配所有字符,除了 '^'. ^ 如果不在集合首位,就没有特殊含义。
在集合内要匹配一个字符 ']',有两种方法,要么就在它之前加上反斜杠,要么就把它放到集合首位。比如, [()[]{}] 和 [{}] 都可以匹配括号。
5| 或
A|B, A 和 B 可以是任意正则表达式,匹配 A 或者 B。任意个正则表达式可以用|连接。扫描目标字符串时,|分隔开的正则样式从左到右进行匹配。当一个样式完全匹配时,这个分支就被接受。
一旦 A 匹配成功, B就不再进行匹配,即便它能产生一个更好的匹配。或者说,'|' 操作符绝不贪婪。如果要匹配 '|' 字符,使用 |, 或者把它包含在字符集里,比如 [|].
6(...)(组合)
匹配括号内的任意正则表达式,并标识出组合的开始和结尾。匹配完成后,组合的内容可以被获取,并可以在之后用 number 转义序列进行再次匹配,之后进行详细说明。
要匹配字符 '(' 或者 ')', 用 ( 或 ), 或者把它们包含在字符集合里: [(], [)].
7断言
(?=…)
当… 匹配时,匹配成功,但不消耗字符串中的任何字符。这个叫做前视断言(lookahead assertion)。比如,Isaac(?!Asimov)将会匹配 'Isaac ' ,仅当其后紧跟 'Asimov' 。
(?!…)
当…不匹配时,匹配成功。这个叫否定型前视断言(negative lookahead assertion)。
例如 Isaac (?!Asimov) 将会匹配 'Isaac ',仅当它后面不是 'Asimov' 。
(?<=…)
如果...的匹配内容出现在当前位置的左侧,则匹配。这叫做肯定型后视断言(positive lookbehind assertion)。
(?<=abc)def 将会在 'abcdef' 中找到一个匹配,因为后视会回退3个字符并检查内部表达式是否匹配。
内部表达式(匹配的内容)必须是固定长度的。abc 或 a|b 是允许的,但是 a* 和 a{3,4} 不可以。
以肯定型后视断言开头的正则表达式,匹配项一般不会位于搜索字符串的开头。
import re
m = re.search('(?<=abc)def', 'abcdef')
print(m.group(0)) # 'def'
m = re.search(r'(?<=-)w+', 'spam-egg')
print(m.group(0)) # 'egg'
(?<!…)
如果...的匹配内容没有出现在当前位置的左侧,则匹配。这个叫做否定型后视断言(negative lookbehind assertion)。
类似于肯定型后视断言,内部表达式(匹配的内容)必须是固定长度的。
以否定型后视断言开头的正则表达式,匹配项可能位于搜索字符串的开头。
Part3正则函数
8re.compile(pattern, flags=0)
将正则表达式的样式编译为一个正则表达式对象(正则对象),通过这个对象的方法 match、search() 等做匹配。
这个表达式的行为可以通过指定标记的值来改变。值可以是任意变量,可以通过位的OR操作( | 操作符)来结合。
prog = re.compile(pattern)
result = prog.match(string)
等价于
result = re.match(pattern, string)
# 匹配字符集abc与字符串匹配的第一个字符。
prog = re.compile('[abc]')
print(prog.search('abcd').group()) # a
如果需要多次使用这个正则表达式的话,使用 re.compile() 和保存这个正则对象以便复用,可以让程序更加高效。
通过 re.compile() 编译后的样式和模块级的函数会被缓存, 所以少数的正则表达式使用无需考虑编译的问题。
9re.search(pattern, string, flags=0)
扫描整个 字符串 找到匹配样式的第一个位置,并返回一个相应的匹配对象。如果没有匹配,就返回一个 None。这和找到一个零长度匹配是不同的。
# w 用来匹配单次字符 包括a-z A-Z 0-9 _
r = re.search('aw+', 'how are you')
# 获取匹配到的结果
print(r.group()) # are
re.match(pattern, string, flags=0)
如果 string 开始的0或多个字符匹配到了正则表达式样式,就返回一个相应的 匹配对象 。如果没有匹配,就返回 None ;注意它跟零长度匹配是不同的。
即便是MULTILINE多行模式, re.match()也只匹配字符串的开始位置,而不匹配每行开始。如果你想定位 string 的任何位置,使用 search()来替代。
# w 用来匹配单次字符 包括a-z A-Z 0-9_
r = re.match('hw+', 'how are you')
# 获取匹配到的结果
print(r.group()) # how
re.fullmatch(pattern, string, flags=0)
如果整个 string 匹配到正则表达式样式,就返回一个相应的匹配对象 。否则就返回一个 None ;注意这跟零长度匹配是不同的。
10re.split(pattern, string, maxsplit=0, flags=0)
用 pattern 分开 string 。如果在 pattern中捕获到括号,那么所有的组里的文字也会包含在列表里。如果 maxsplit 非零, 最多进行 maxsplit 次分隔, 剩下的字符全部返回到列表的最后一个元素。
# 按照 “;"或者",” 对字符串进行分割
re.split('[;,]', 'abc,qwer; opq, mn')
# ['abc', 'qwer', ' opq', ' mn']
>>> re.split(r'W+', 'Words, words, words.')
['Words', 'words', 'words', '']
>>> re.split(r'(W+)', 'Words, words, words.')
['Words', ', ', 'words', ', ', 'words', '.', '']
>>> re.split(r'W+', 'Words, words, words.', 1)
['Words', 'words, words.']
>>> re.split('[a-f]+', '0a3B9', flags=re.IGNORECASE)
['0', '3', '9']
如果分隔符里有捕获组合,并且匹配到字符串的开始,那么结果将会以一个空字符串开始。对于结尾也是一样:
>>> re.split(r'(W+)', '...words, words...')
['', '...', 'words', ', ', 'words', '...', '']
这样的话,分隔组将会出现在结果列表中同样的位置。样式的空匹配仅在与前一个空匹配不相邻时才会拆分字符串。
>>> re.split(r'b', 'Words, words, words.')
['', 'Words', ', ', 'words', ', ', 'words', '.']
>>> re.split(r'W*', '...words...')
['', '', 'w', 'o', 'r', 'd', 's', '', '']
>>> re.split(r'(W*)', '...words...')
['', '...', '', '', 'w', '', 'o', '', 'r', '', 'd', '', 's', '...', '', '', '']
11re.findall(pattern, string, flags=0)
返回 pattern 在 string 中的所有非重叠匹配,以字符串列表或字符串元组列表的形式。对 string 的扫描从左至右,匹配结果按照找到的顺序返回。
空匹配也包括在结果中。返回结果取决于模式中捕获组的数量。
如果没有组,返回与整个模式匹配的字符串列表。
如果有且仅有一个组,返回与该组匹配的字符串列表。
如果有多个组,返回与这些组匹配的字符串元组列表。非捕获组不影响结果。
# 匹配包含所有带有o的单词
re.findall('wow+', 'how are you')
# ['how', 'you']
re.findall(r'bf[a-z]*', 'which foot or hand fell fastest')
# ['foot', 'fell', 'fastest']
re.findall(r'(w+)=(d+)', 'set width=20 and height=10')
# [('width', '20'), ('height', '10')]
12re.finditer(pattern, string, flags=0)pattern
在 string 里所有的非重复匹配,返回为一个迭代器 iterator 保存了匹配对象 。string 从左到右扫描,匹配按顺序排列。空匹配也包含在结果里。
13re.sub(pattern, repl, string, count=0, flags=0)
返回通过使用 repl 替换在 string 最左边非重叠出现的 pattern 而获得的字符串。
如果样式没有找到,则不加改变地返回 string。
repl 可以是字符串或函数;如为字符串,则其中任何反斜杠转义序列都会被处理。
如果repl是一个函数,那它会对每个非重复的 pattern 的情况调用。这个函数只能有一个匹配对象参数,并返回一个替换后的字符串。
可选参数 count 是要替换的最大次数;count 必须是非负整数。如果省略这个参数或设为 0,所有的匹配都会被替换。
def dashrepl(matchobj):
... if matchobj.group(0) == '-': return ' '
... else: return '-'
>>> re.sub('-{1,2}', dashrepl, 'pro----gram-files')'pro--gram files'
>>> re.sub(r'sANDs', ' & ', 'Baked Beans And Spam', flags=re.IGNORECASE)
'Baked Beans & Spam'
14re.escape(pattern)
转义 pattern 中的特殊字符。如果你想对任意可能包含正则表达式元字符的文本字符串进行匹配,它就是有用的。
>>> print(re.escape('https://www.python.org'))
https://www.python.org
>>> legal_chars = string.ascii_lowercase + string.digits + "!#$%&'*+-.^_`|~:"
>>> print('[%s]+' % re.escape(legal_chars))
[abcdefghijklmnopqrstuvwxyz0123456789!#$%&'*+-.^_`|~:]+
>>> operators = ['+', '-', '*', '/', '**']
>>> print('|'.join(map(re.escape, sorted(operators, reverse=True))))
/|-|+|**|*
15函数对比
match(pattern,string):匹配字符串的开头,如果开头匹配不上,则返回None;
seach(pattern,string):扫描整个字符串,匹配后立即返回,不在往后面匹配;
findll(pattern,string):扫描整个字符串,以列表形式返回所有的匹配值;
split(pattern,string):按照某个匹配的正则表达式,将整个字符串切分后,以列表返回;
sub(pattern, repl, string):按照某个匹配的正则表达式,将整个字符串的某个字串替换为另外一个字串。
Part4正则表达式工具
分享几个私藏好用的正则表达式网站工具,可视化正则表达式和学习教程。
https://github.com/CJex/regulex
https://devtoolcafe.com/tools/regex#!flags=img&re=
https://github.com/Bowen7/regex-vis
https://ihateregex.io/
https://github.com/geongeorge/i-hate-regex
https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md
https://regexlearn.com/zh-cn
https://github.com/aykutkardas/regexlearn.com
python官方正则表达式教程:
https://docs.python.org/zh-cn/3/library/re.html#module-contents

2023-02-27

2023-02-02

2022-12-07

2023-02-27

 星标公众号,精彩不错过
星标公众号,精彩不错过
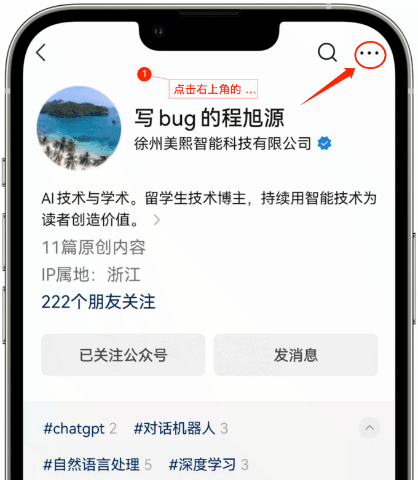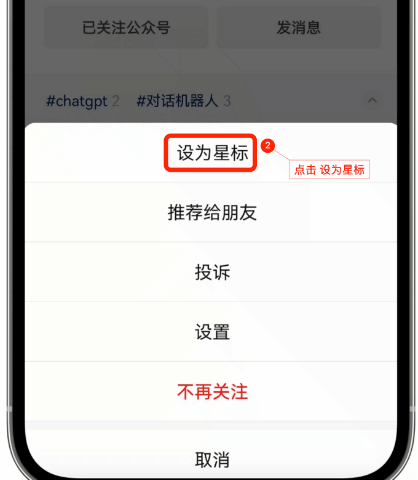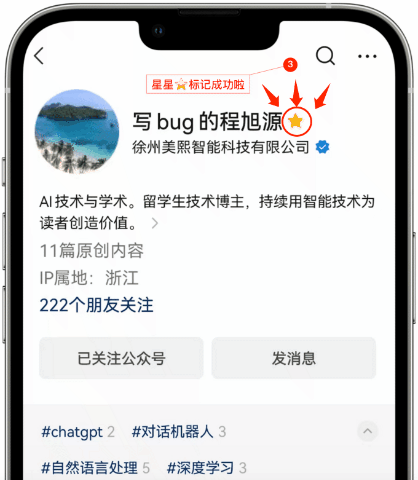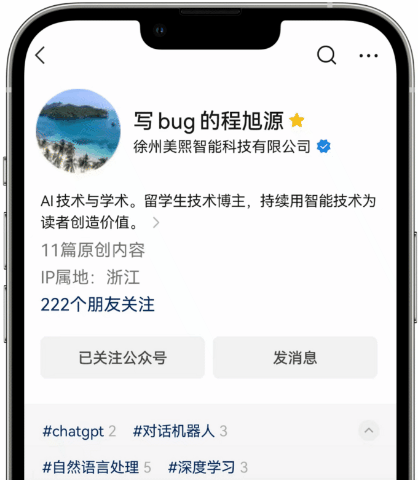


“点赞”是喜欢,“在看、分享”是真爱
<